ResNet获得了2015年ILSVER比赛中图像分类第一名,目标检测第一名。获得COCO数据集比赛中目标检测第一名,图像分割第一名。该网络亮点在于引入残差模块来缓解随着网络深度的增加而出现的网络退化问题。
论文:
ResNet:Deep Residual Learning for Image Recognition
ResNet V2:Identity Mappings in Deep Residual Networks
Part Ⅰ : ResNet
Introduction
在ResNet出现之前,人们已经认同神经网络深度的增加可以提高模型的准确率这一观点。但在实际训练网络的过程中,常会出现这样的现象:模型的准确率随网络的深度增加上升到一定程度之后,准确率反而随网络的深度增加而下降。
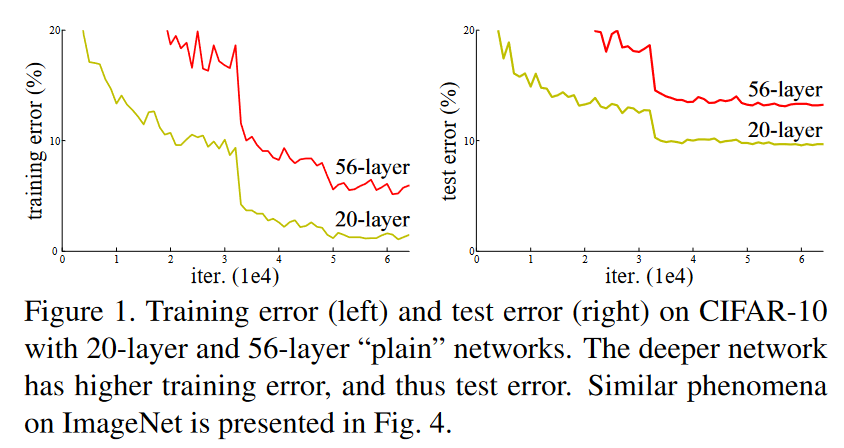
造成这样现象的原因有两个:梯度爆炸/梯度消失问题和网络退化问题。
梯度爆炸/梯度消失
根据反向传播算法中的链式法则,如果层层之间的梯度均在(0,1)之间,层层缩小,那么就会出现梯度消失。反之,如果层层传递的梯度大于1,那么经过层层扩大,就会出现梯度爆炸。
要解决因网络深度增加而出现的梯度爆炸/梯度消失问题,可以使用BN(Batch Normalization)来解决。
网络退化
网络退化是指当神经网络越来越深的时候,反传回来的梯度之间的相关性会越来越差,最后接近白噪声。为了缓解网络退化问题,作者引入了残差学习的思想。
Deep Residual Learning
”若某一较深的网络多出另一较浅网络的若干层有能力学习到恒等映射,那么这一较深网络训练得到的模型性能一定不会弱于该浅层网络。”
作者认为,如果能够通过某种方法,使得较深层的网络能够恒等映射浅层网络,那么其模型性能一定不会差于该浅层网络。这就是参差模块的核心思想:通过增加一条短路连接(shortcut connection)来实现网络的恒等映射(identity mapping)。
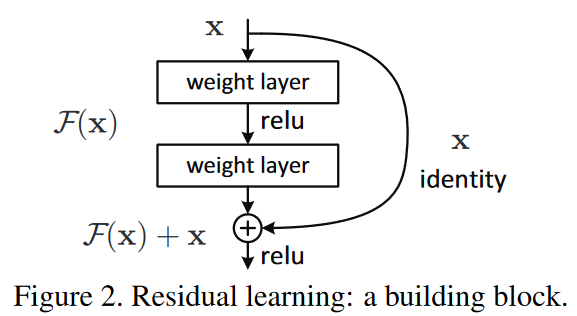
上图就是作者提出的参差模块:输入x经过两个卷积层后得到的结果F(x),与经过shortcut connection的x相加后,再进行ReLU运算。
对于一个堆积层结构(几层堆叠而成),当输入为x时其学习到的特征记为H(x),现在我们希望其可以学习到残差 F(x)=H(x)−x ,这样原始的学习特征则是 F(x)+x 。对于神经网络来说,学习F(x)=0要比学习H(x)=x简单得多。因为对于前者而言,我们只需在学习F(x)=0时让其参数为0即可。
Network Architectures
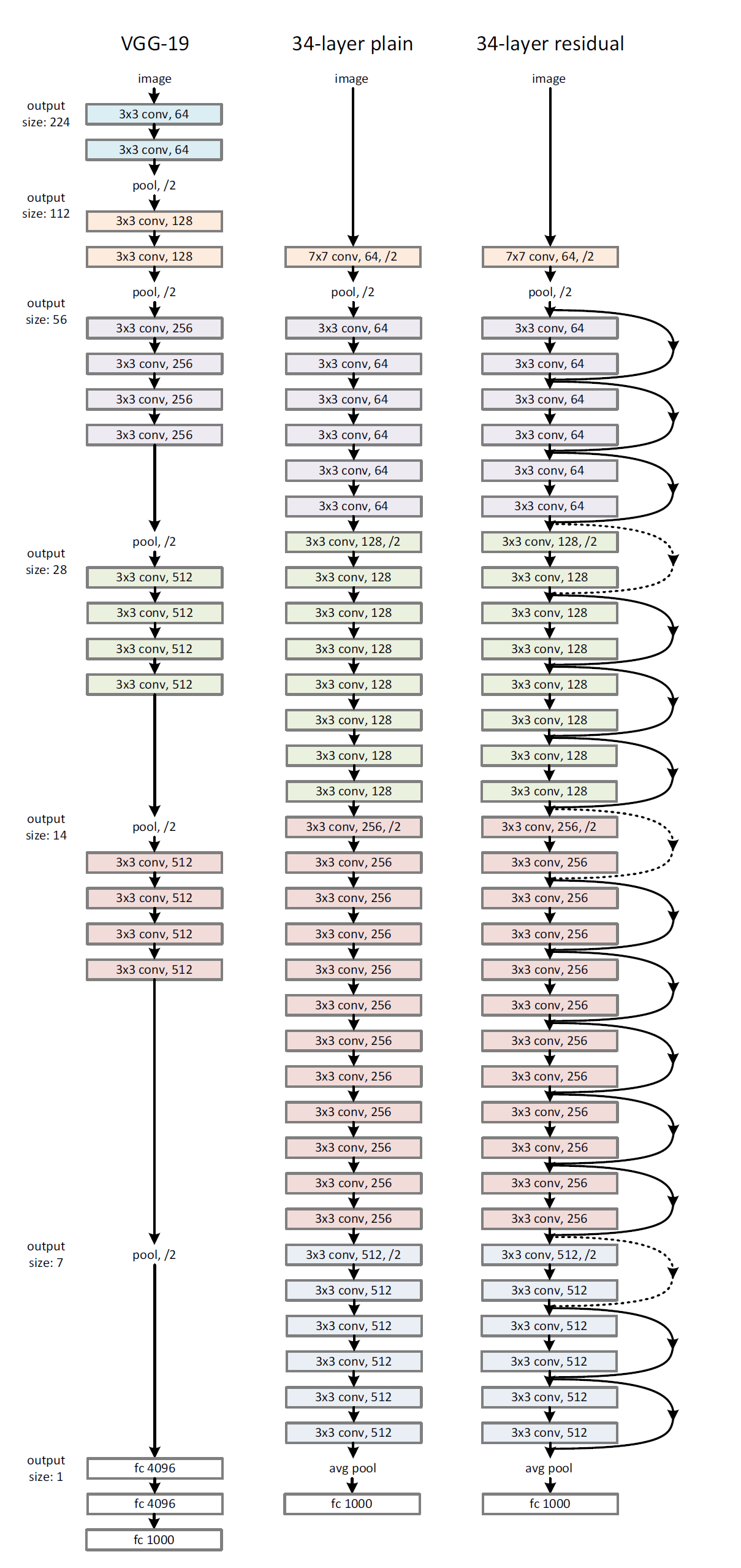
上图是ResNet34的网络结构,可以看出与同为34层的plain network相比,ResNet增加了许多shortcut connection。ResNet34根据颜色被分为5个模块(分别对应下表中展示的5个网络层)。
需要注意的是,在第3、4、5模块(图中标注为绿色、红色、蓝色的部分)的起始位置的shortcut connection被标注为虚线。这是因为在这些地方,图像在经过residual模块时需要进行下采样操作。具体实现方法为:在residual分支中通过3x3conv, stride=2实现图像下采样;在shortcut分支中,此时的输入x则需要经过一个1x1conv的卷积来实现下采样。这样两个分支汇合时才能进行add操作。
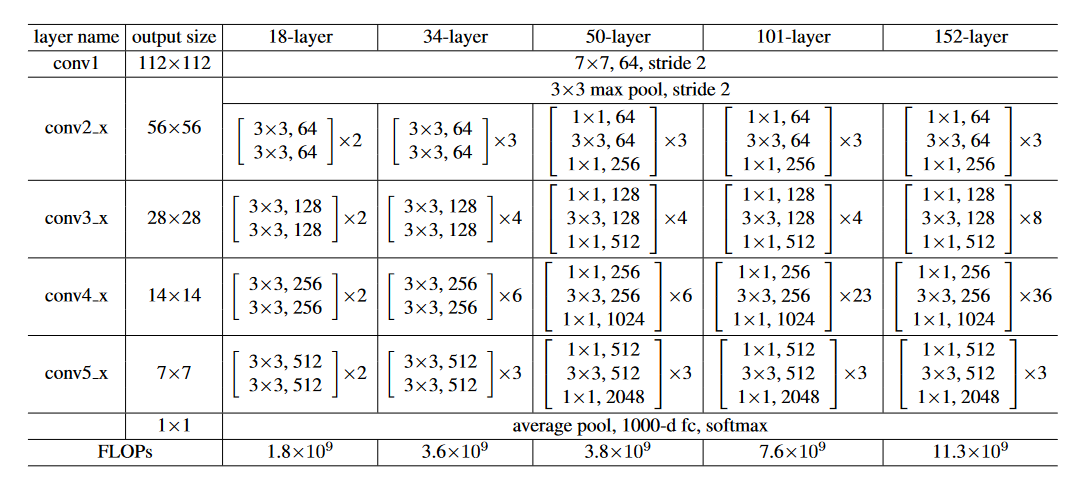
上表是作者给出的不同层数的ResNet的具体网络结构。虽然不同网络的具体层数不同,但是总体的结构是一致的,即均是由5个卷积模块堆叠后接一个avg pool,然后fc 1000输出分类结果。
在上表中,ResNet-50,ResNet-101和ResNet-152使用了一种名为瓶颈(bottleneck)的残差模块。我们下面将对这种结构进行进一步介绍。
bottleneck
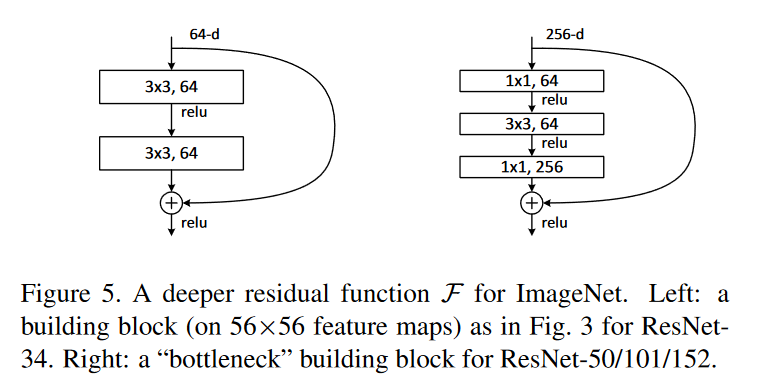
上图中左边展示的是原本的参差模块结构,右边则是bottleneck结构。可以看出,bottleneck中,卷积层由两个3x3的卷积变为了1x1, 3x3, 1x1的三层卷积层。其中,前后两个1x1conv的作用是分别对图像进行降维,升维的操作。对于网络层数较多的ResNet-50/101/152来说,这种做法可以有效地减少参数量计算量。
Part Ⅱ : ResNet V2
未完待续。。。