prompt是NLP领域最新兴起的预训练范式,其主要方法是在预训练的过程中结合输入文本给出与下游任务相关的提示,让模型在训练过程中进行预测。本篇博客主要介绍NLP领域语言模型的四个发展阶段、prompt基本形式的数学定义以及相关的背景知识。
1. Background Knowledge
本部分内容都可以分别展开详述,此处仅作简单概念介绍。
Zero-shot Learning
Zero-shot Learning(ZSL),又称零样本学习。ZSL的目标是让模型具有推断能力,能够根据一些具体的描述分类出在训练中不曾学习过的类别对象(Zero-shot的来源)。
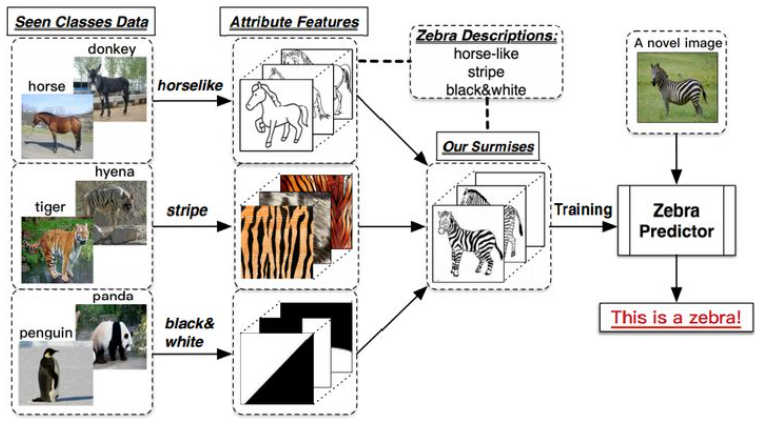
举个例子,假设模型通过训练可以识别出马、老虎以及熊猫这三种类别的动物。并且能够从中抽取出不同类别的特征,比如:马的外形特征,老虎的条纹状特征以及熊猫的黑白色特征。此时当我们给出对于斑马的描述(外形像马、黑白色、条纹)时,我们希望模型能够识别出斑马。
Few-shot Learning
Few-shot Learning(FSL),又称少样本学习。意思是面对一个新的类别,模型只需要少量的样本就能够学习。Few-shot Learning是Meta Learning(元学习)在监督学习领域的应用。
该领域的一个常用术语叫做 N-way K-shot,表示在训练阶段,使用N个类别,每个类别K个样本的数据作为训练数据,让模型从小样本的数据中学习如果对这N个类别进行分类。
One-shot Learning
可以看作一种特殊情况下的Few-shot Learning,此时训练阶段不同类别的样本只有一个。
2. Two Sea Changes in NLP
Feature Engineering
早期的NLP模型依赖于"Feature Engineering",工程师利用他们了解的领域内的知识从有限的数据中提取特征。
Architecture Engineering
神经网络面世之后,NLP领域的模型转向了"Architecture Engineering"。在这个阶段,模型自己学习特征
Objective Engineering
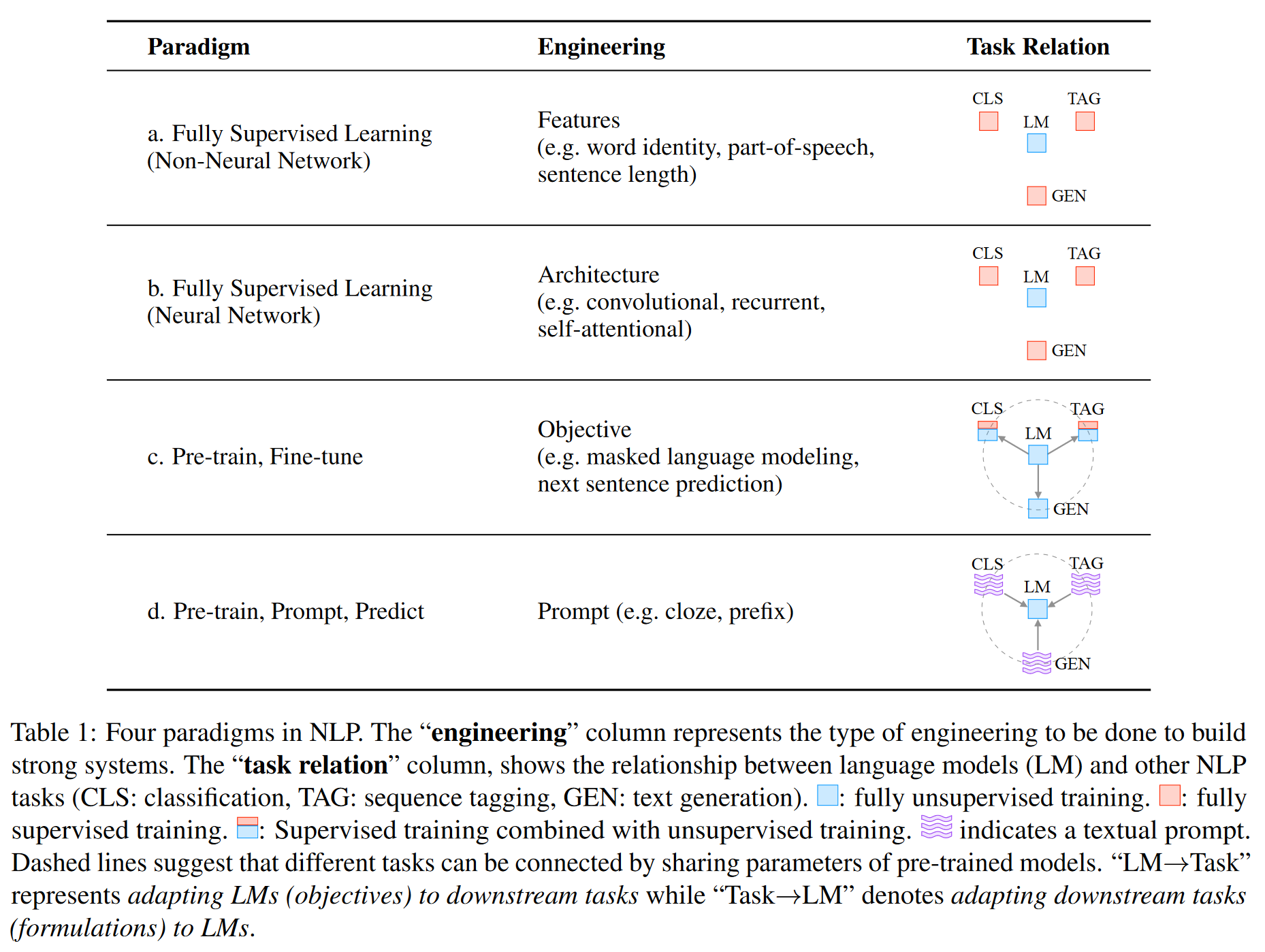
从2017年至2019年,NLP领域迎来了一次巨变。有监督模型的重要性逐渐降低。这时期,人们将注意力转移到“预训练-微调”的模型范式上。在这种范式中,有着固定结构的模型作为语言模型被提前预训练好。这些语言模型可以在海量的数据集上进行预训练,在这个过程中模型就可以学习到这个语言相关的特征信息。经过预训练的语言模型接下来会通过微调应用于不同的下游任务。在这种范式中,人们的注意力主要在于"Objective Engineering",即设计能应用在预训练阶段和微调阶段的训练目标。
Prompt Engineering
现在我们正处于NLP领域的第二次巨变的过程中,我们正由“预训练-微调”的范式过渡到“预训练-提示-预测”(pre-train, prompt, predict)范式。不同于之前通过objective engineering让预训练模型去适应不同的下游任务,prompt的重点在于借助“提示”的方法让下游任务可以直接在模型预训练的阶段进行训练。
比如说对于情感分析任务,对于输入语句”我今天错过了公交车“,我们可以在后面加上”我感觉十分___“的提示语句,让模型用表达情感的词来填空。通过这种方法,我们可以操控预训练模型去预测我们想要的输出,有时甚至不需要额外的和具体任务相关的训练。
prompt的优点在于:当我们给出合适的提示后,我们可以用一个无监督方式训练的语言模型去解决很多任务。
这种范式应用的关键之处在于"Prompt Emgineering",即为当前的语言模型找一个最合适的prompt。
3. A Formal Description of Prompting
Supervised Learning in NLP
NLP的传统监督学习模式下,我们通常选择文本作为输入x,通过模型P (y|x; θ)预测输出y。y可以是一个标签、文本或是其他形式的输出。为了学习到模型的中的参数,我们使用包含输入-输出对的数据集来训练模型,去预测条件概率。
举例如下:
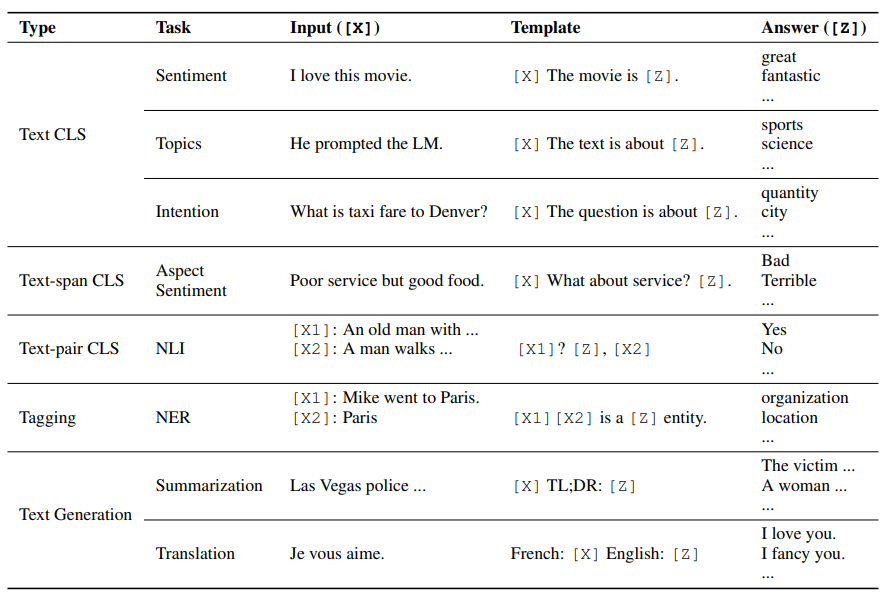
1、文本分类:选用文本作为输入x,从固定的标签集中选择一个标签作为输出y。如情感分析。
2、条件文本生成 conditional text generation:通过输入文本x生成另一个文本y。如机器翻译。
Prompting Basics
有监督学习方式的主要问题在于,为了训练一个模型需要大量的带标签的数据集。但是对于许多任务来说,这样大量的数据集很难找到。NLP方向的基于提示的学习方法试图通过学习语言模型来避开这个问题。语言模型根据输入文本x直接学习概率,然后根据这个概率去预测y,以此来减少或避免对于大型的带标签的数据集的需求。
本节给出提示的最基础的数学描述,既包含关于提示的许多工作,也可以扩展到其他的工作。
基础的提示(Basic Prompting)通过三个步骤预测最高得分的输出y
Step 1: Prompt Addition 添加提示
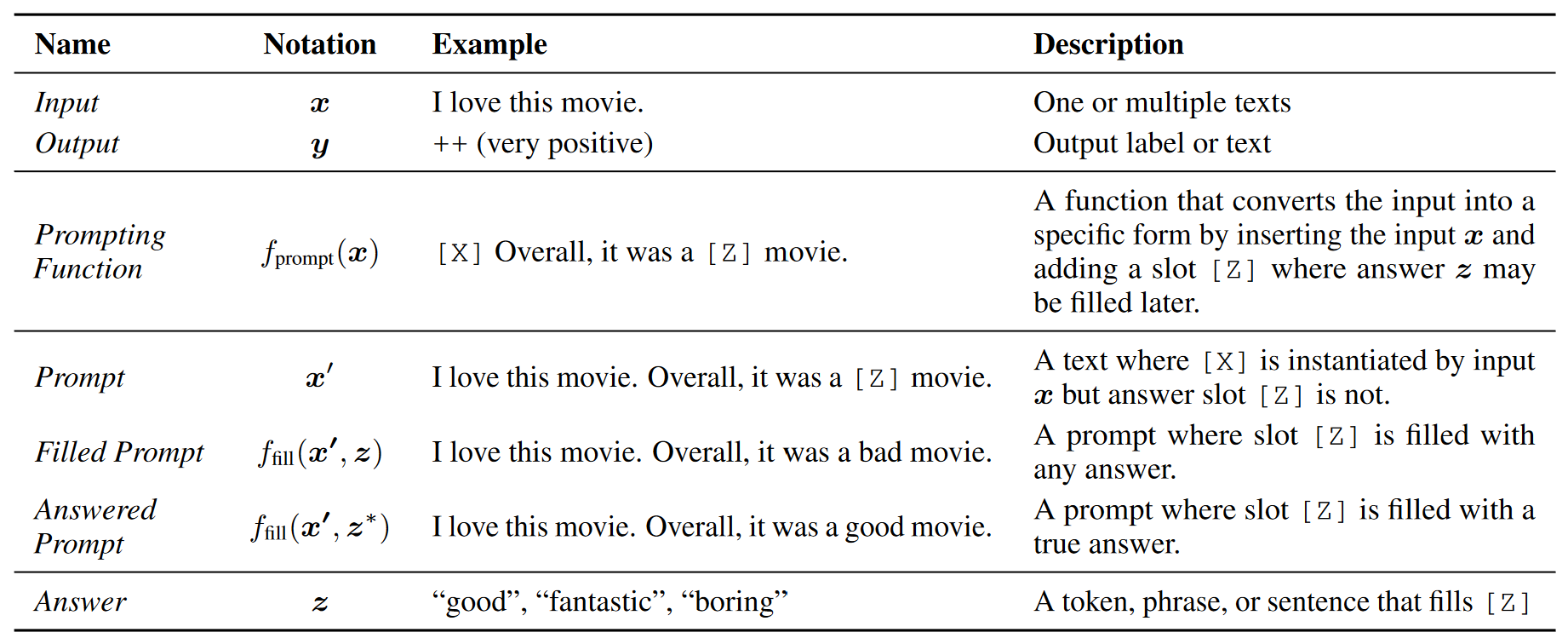
需要一个提示函数fprompt(·)将输入x变为提示x’,在之前的大多数工作中,这一函数通常分为两步:
1、使用一段包含两处空缺的文本作为模板。一个input slot用于输入[X],一个answer slot用于输出中间生成答案[Z],文本z将在后面被映射为y。
2、将输入x填入slot[X]处。
Notes:
-
prompt分类
- cloze prompt: 将slot放在文本中间的位置。
- prefix prompt: 将slot放在文本的末尾处。
-
prompt不一定要是文字,也可以是虚拟文字(如数字id),或直接生成连续的向量
-
和[Z]的slots数量可以根据任务的需要灵活改变。
Step 2: Answer Search
这一步的目标是寻找一个是让LM得分最高的文本z。我们设定Z集合作为z的答案的集合。Z可以是自然语言的集合(适用于语言生成任务),也可以是固定词的集合(适用于文本分类任务)。
我们接着定义一个函数 ffill(x′, z),对于一个prompt x填入一个潜在答案z。我们把进行过这一操作的prompt称为filled prompt。如果提示里填写的是正确答案,我们称其为answered prompt
最后,我们用预训练的语言模型在Z集合内的潜在答案中计算求对应的filled prompt的概率。
Step 3: Answer Mapping 答案映射
最后,我们要根据得分最高的答案z得到得分最高输出结果y。这一映射在大多数的情况下都是繁琐的,因为在一些场景下答案本身就是最后的输出结果。但对于情感分析这种文本分类任务来说,可能不同的z对应的输出y是相同的。所以需要有答案映射这一步骤。
Design Considerations for Prompting
简单介绍一些设计提示是需要考虑的方面,更具体的细节在后续文章详细介绍:
- Pre-trained Model Choice: 许多预训练模型都可以同来计算概率。
- Prompt Engineering: 不同的prompt不仅对准确率有很大的影响,同样也有各自适合的不同任务。
- Answer Engineering: 根据任务的不同,我们构建的Z集合以及相应的映射函数也不同。
- Expanding the Paradigm: 上面提到的公式仅用来描述prompt中最基础一些模型架构。对于这个范式还有很多拓展的方法。
- Prompt-based Training Strategies: 对于语言模型的参数,以及prompt的参数以及两者结合的参数的训练都有很多方法。在第7节会对不同的训练策略以及他们相应的优点进行总结。