GoogLeNet是google提出的基于Inception模块的串并联网络架构,并获得了2014年ILSVRC比赛的分类任务的冠军(同年该项亚军为VGG)。Inception模块及其迭代改进的版本可以提升模型的泛化能力、降低模型参数。
Part 1 : GooLeNet
论文:Going Deeper with Convolutions
Abstract & Introduction
GoogLeNet在ILSVRC14的分类和检测比赛中达到了新高度。这种网络结构提高了网络内计算资源的利用率,在保持计算量不变的同时增加网络的宽度和深度。GoogLeNet的网络架构思想基于Hebbian原则和多尺度处理的直觉,并且提出的Inception模块可以增加网络的深度。
Motivation and High Level Considerations
要提高深度神经网络的性能,最直接的方法就是增大规模。增大网络规模的方式有两种:
- 增加网络深度(网络层数量)
- 增加网络宽度(每层的神经元数量)
但直接增大网络规模的这种方法存在两个主要缺点:
- 更大的规模意味着更多的参数,这会使得规模大的网络会更容易过拟合;
- 更大的规模会造成计算资源的急剧增加,如果增加的部分的效率并不高,那么大量的计算资源都因此被浪费了。
解决这两个问题的最根本的方法就是将网络结构(包括卷积层内部)彻底从全连接(fully connected)变为稀疏连接(sparsely connected),对此有生物系统模拟和Arora等人的研究可佐证。但在实际应用中,将全连接变为稀疏连接后计算量并没有很大提升,这是因为现有硬件是针对密集矩阵进行计算优化的。由此提出Inception模块,在使用现有的计算稠密稀疏矩阵的硬件设备的条件下,利用稀疏连接提高网络的性能。
Architectural Details
Inception module
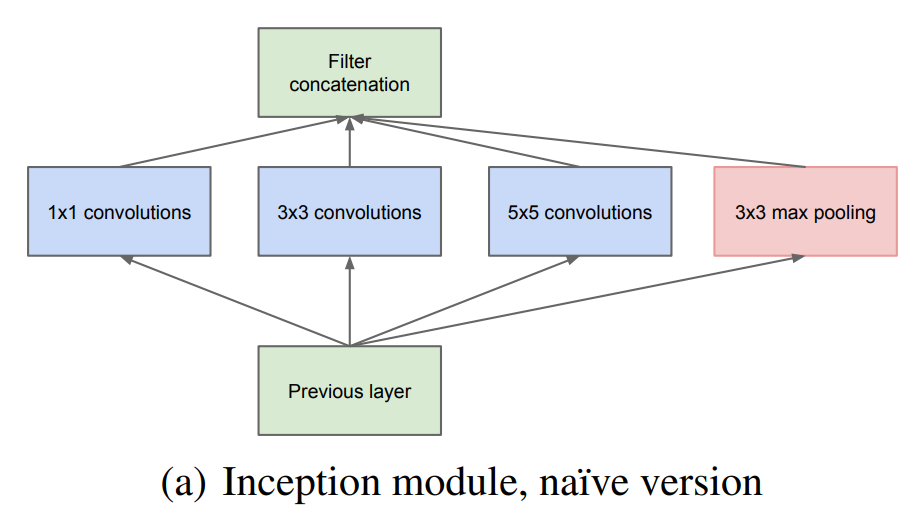
Inception v1模块,将1x1,3x3,5x5 conv和3x3 pooling组成并联网络。一方面增加了网络的宽度,另一方面增加了网络对不同尺度的适应性(不同大小的卷积核支路所对应的感受野不同)。
Inception module with dimension reductions
对于最初设计的Inception模块,虽然5x5的卷积核较少,但当网络达到一定规模后,仍然会产生巨大的计算量。为了解决这个问题,作者引入1x1的卷积核进行降维。对Inception v1的改进如下图所示:
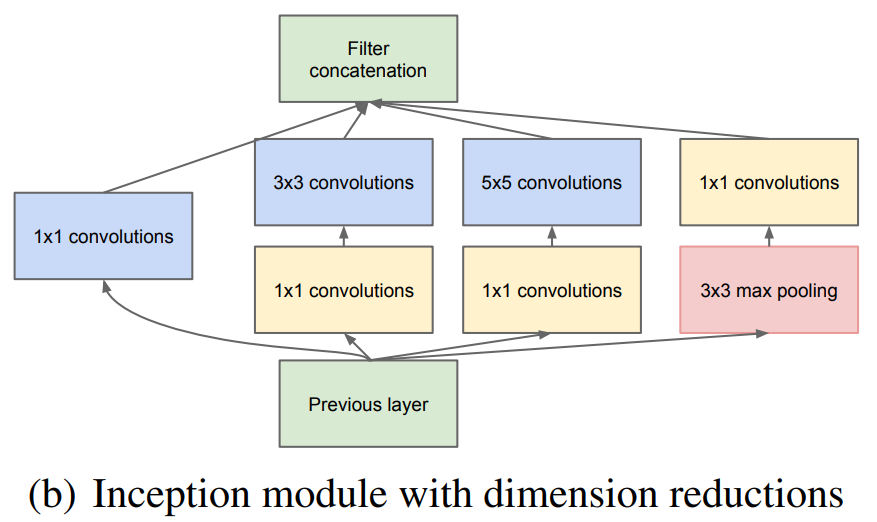
改动后的结构有两个优点:
- 通过降维,可以减少模型参数量;
- 新增1x1卷积后可以带来更多的非线性变换,提高模型表达能力。
GoogLeNet
GoogLeNet的网络细节如下表所示:
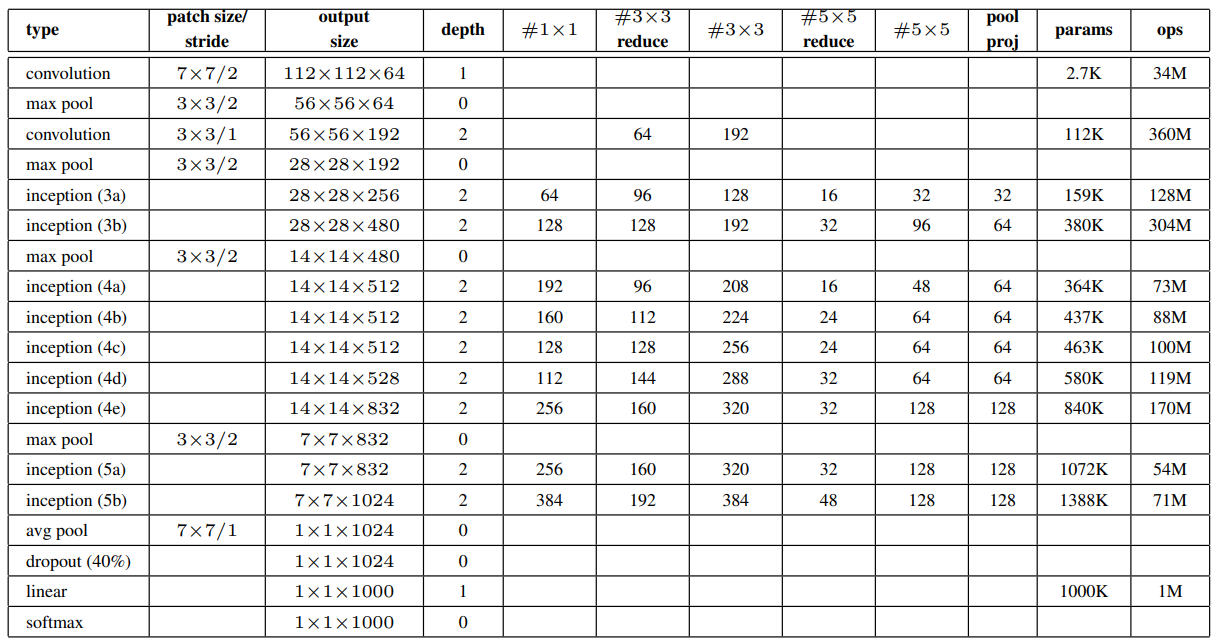
网络的一些特点如下:
- 网络采用了模块化的结构,使用Inception mudule,便于修改网络结构。
- 包括Inception在内的所有卷积都使用修正线性激活(ReLU)。
- 网络使用average pooling代替了全连接层,但仍需要保留dropout。
- 梯度回传:为了避免梯度消失,网络中额外增加了2个辅助分类器(softmax)用于向前传播梯度。(辅助分类器只在训练时使用)
Conclusions
将最佳稀疏结构稠密化是提高计算机视觉神经网络的有效方法。相比于浅且窄的网络,这种方法的优点在于只需适度增加计算量,性能就显著提升。
Part 2 : Inception系列
论文:
Rethinking the Inception Architecture for Computer Vision
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
Inception V2
4条设计原则
文章提出了4条设计原则,并依据这4条原则对Inception进行改进:
- 网络浅层慎用bottleneck
- 高维特征更适合在网络局部处理
- 网络聚合可以通过低维嵌入
- 平衡网络的深度和宽度
Inception V2 结构
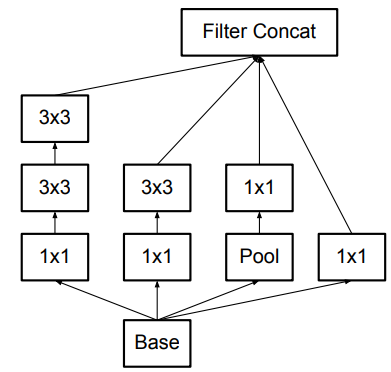
Inception v2相对于v1做的改进是使用多个小卷积核代替一个大卷积核(如使用2个3x3的卷积代替原来的1个5x5卷积),这样可以有效减少模型的参数量,增加模型的深度。
此外,Inception v2还引入了BN,加速网络训练,解决梯度消失。
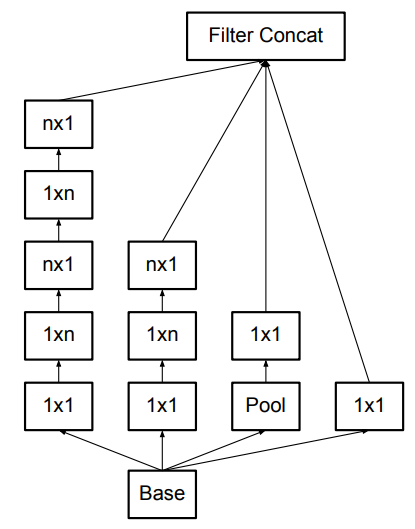
在此基础上,作者提出可以使用多个非对称的小尺寸卷积核堆叠,代替一个大卷积核(比如用1xn和nx1代替nxn)。需要注意的是,这种结构在前几层的效果并不好,当特征图的尺寸在12到20之间时使用的效果会更好一些。
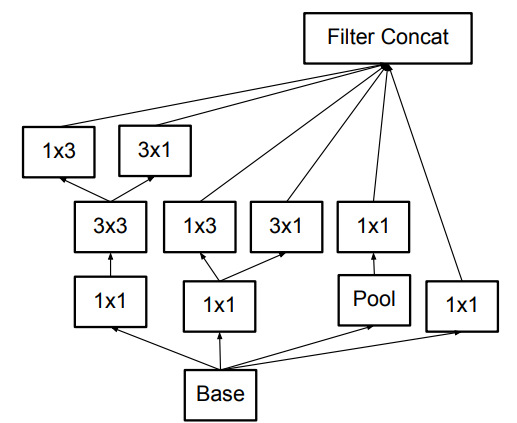
结合对称卷积和非对称卷积,增加网络宽度。
Inception V3
Inception v3中作者将7x7卷积分解成了3个3x3卷积,v3中使用的Aug loss里使用了BN进行regularization。
降低特征图大小
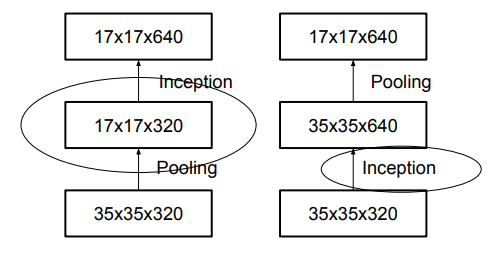
传统的两种下采样方式如上图所示,要么先pooling再Inception(这种方法的缺点是池化会造成信息的丢失),要么先Inception再Pooling(这种方法的缺点是计算量增大)。故两种方法都不可取。作者提出了一种新的降低特征图大小的方法,如下图所示:
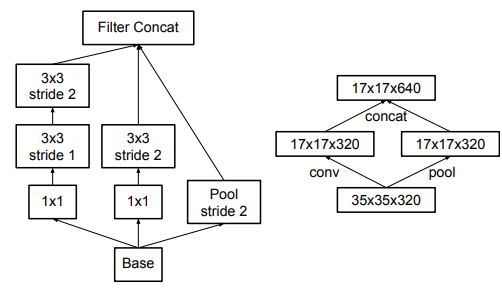
让池化和卷积并行执行(stride=2),最后再将特征图进行组合。
Inception V4
整体网络结构
相比于v2/v3,Inception v4的网络结构更加简介同意,并使用了更多的Inception模块。下图为Inception v4的网络结构。
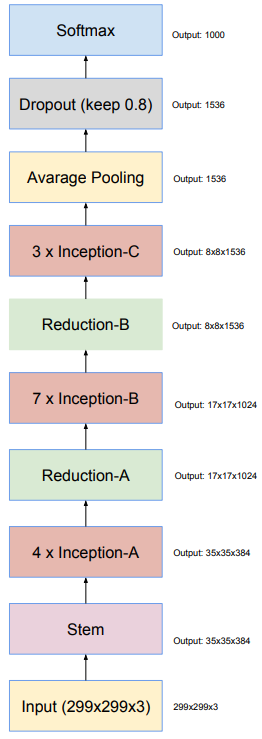
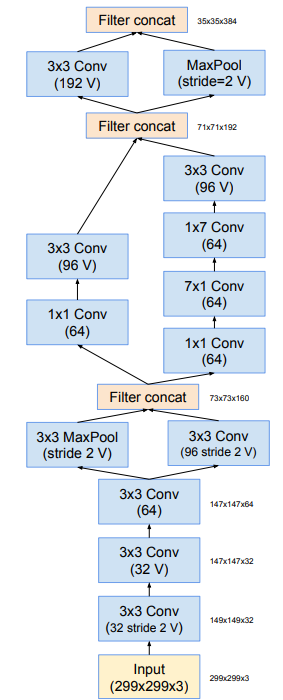
下图为Inception v4的stem模块。
Inception ResNet
Inception ResNet将Inception模块与残差连接思想结合,该系列有Inception-ResNet-v1和Inception-ResNet-v2,经验证,残差连接能够显著加速Inception的训练。