AlexNet在2012的ImageNet的竞赛中获得了冠军,该模型由Hintom和他的学生Alex Krizhevsky等人提出。 AlexNet由5个卷积层和3个全连接层构成,并首次使用ReLU、LRN、Dropout等技巧来提高网络的准确率。
论文:AlexNet
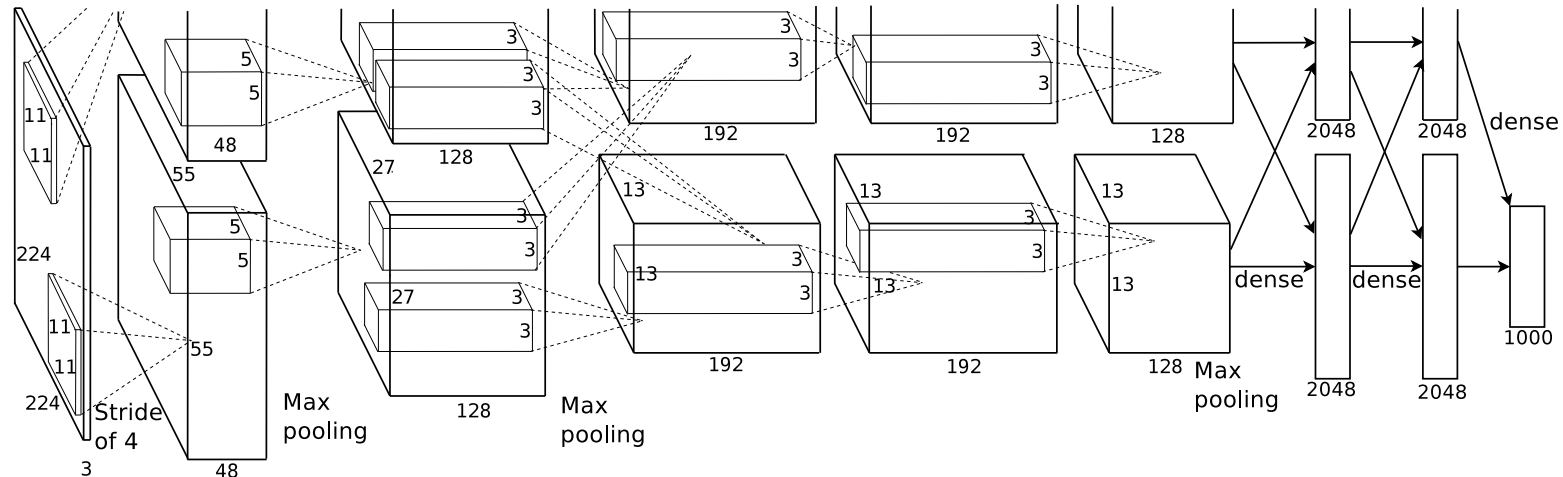
AlexNet架构
Tricks
AlexNet应用的一些特殊的方法(按重要性进行排序)
ReLU
AlexNet首次使用ReLU函数代替sigmoid和Tanh作为激活函数,这是因为相比于后两个函数,ReLU可以更好的解决梯度消失的问题。当ReLU函数的输入大于0时直接返回原值,输入小于0时则返回0。这样既可以利用正输入的梯度为1这个特点解决梯度消失问题,也可以利用负输入的输出为0这一特性,增加模型的稀疏性表示,进而加速并简化模型。(需要注意的是,ReLU常作为CNN的激活函数,但通常情况下并不适合作为RNN的激活函数)
多GPU训练
由于GTX 580 GPU只有3GB的内存,因此将AlexNet网络分布在两块GPU上进行训练。需要额外注意的是,在训练时,GPU只在某些特定的层上进行通信,比如第3层的核会将第2层的所有核映射作为输入,第4层的核只将位于同一GPU上的第3层的核映射作为输入(这一点在网络架构图中可以看出)。
LRN (局部响应归一化)
局部响应归一化 (Local Response Normalization) 通过模拟生物医学中的“侧抑制”(被激活的神经元会抑制周围的神经元)来实现局部抑制,增强模型的泛化能力。(注:现在LRN已经逐渐被BN所取代)
归一化的优点
- 加快收敛速度
- 提高模型精度
重叠池化
通常池化的窗口大小z与步长s相等,因此池化作用的区域不存在重叠的部分。但重叠池化令z>s,使得池化区域之间存在重叠的部分。AlexNet这篇论文指出,采用重叠池化的模型更不容易过拟合。
减少过拟合
AlexNet主要使用两种方法来克服过拟合。
数据增强
AlexNet用两种方式实现数据增强。因这两种方式都是由原始图像经非常少的计算量产生变换得到的图像,因此无需存储在硬盘上。
- 随机裁剪、水平翻转
- 改变训练图像的RGB通道的强度:对RGB像素值集合执行PCA,并对主成分做一个标准差为0.1的高斯扰动。
Dropout
在训练过程中以p=0.5的概率对每个隐层神经元的输出设为0,以此丢弃部分神经元。这些被丢弃的神经元将不再进行前向传播并且不参与反向传播。采用droput方法可以避免过拟合。